
★ Free/libre software · This software is provided 100% free of charge · No adware or spyware! ★
Dynamic Audio Normalizer is a library for advanced audio normalization purposes. It applies a certain amount of gain to the input audio in order to bring its peak magnitude to a target level (e.g. 0 dBFS). However, in contrast to more "simple" normalization algorithms, the Dynamic Audio Normalizer dynamically re-adjusts the gain factor to the input audio. This allows for applying extra gain to the "quiet" sections of the audio while avoiding distortions or clipping the "loud" sections. In other words: The Dynamic Audio Normalizer will "even out" the volume of quiet and loud sections, in the sense that the volume of each section is brought to the same target level. Note, however, that the Dynamic Audio Normalizer achieves this goal without applying "dynamic range compressing". It will retain 100% of the dynamic range within each "local" region of the audio file.
The Dynamic Audio Normalizer is available as a small standalone command-line utility and also as an effect in the SoX audio processor as well as in the FFmpeg audio/video converter. Furthermore, it can be integrated into your favourite DAW (digital audio workstation), as a VST plug-in, or into your favourite media player, as a Winamp plug-in. Last but not least, the "core" library can be integrated into custom applications easily, thanks to a straightforward API (application programming interface). The "native" API is written in C++, but language bindings for C99, Microsoft.NET, Java, Python and Pascal are provided.
A "standard" (non-dynamic) audio normalization algorithm applies the same constant amount of gain to all samples in the file. Consequently, the gain factor must be chosen in a way that won't cause clipping (distortion), even for the input sample that has the highest magnitude. So if S_max denotes the highest magnitude sample in the whole input audio and Peak is the desired peak magnitude, then the gain factor will be chosen as G=Peak/abs(S_max). This works fine, as long as the volume of the input audio is constant, more or less. If, however, the volume of the input audio varies significantly over time – as is the case with many "real world" recordings – the standard normalization algorithm will not give satisfying result. That's because the "loud" parts can not be amplified any further (without distortions) and thus the "quiet" parts will remain quiet too.
Dynamic Audio Normalizer solves this problem by processing the input audio in small chunks, referred to as frames. A frame typically has a length 500 milliseconds, but the frame size can be adjusted as needed. The Dynamic Audio Normalizer then finds the highest magnitude sample within each frame, individually and independently. Next, it computes the maximum possible gain factor (without distortions) for each individual frame. So, if S_max[n] denotes the highest magnitude sample within the n-th frame, then the maximum possible gain factor for the n-th frame will be G[n]=Peak/abs(S_max[n]). Unfortunately, simply amplifying each frame with its own "local" maximum gain factor G[n] would not produce a satisfying overall result either. That's because the maximum gain factors can vary strongly and unsteadily between neighboring frames! Therefore, applying the maximum possible gain to each frame without taking neighboring frames into account would result in a strong dynamic range compression – which not only has a tendency to destroy the "vividness" of the audio but could also result in the "pumping" effect, i.e fast changes of the gain factor that become clearly noticeable to the listener.
The Dynamic Audio Normalizer tries to avoid these issues by applying an advanced dynamic normalization algorithm. Essentially, when processing a particular frame, it also takes into account a certain neighborhood around the current frame, i.e. the frames preceding and succeeding the current frame will be considered as well. However, while information about "past" frames can simply be stored as long as they are needed, information about "future" frames are not normally available. A simple approach to solve this issue would be using a 2-Pass algorithm, but this would require processing the entire audio file twice – which also makes stream processing impossible. The Dynamic Audio Normalizer uses a different approach instead: It employs a tall "look ahead" buffer. This means that that all audio frames will progress trough an internal FIFO (first in, first out) buffer. The size of this buffer is chosen sufficiently large, so that a frame's complete neighborhood, including the subsequent frames, will already be present in the buffer when that particular frame is being processed. The "look ahead" buffer eliminates the need for 2-Pass processing and thus gives an improved performance. It also makes stream processing possible.
With information about the frame's neighborhood available, a Gaussian smoothing kernel can be applied on those gain factors. Put simply, this smoothing filter "mixes" the gain factor of the n-th frames with those of its preceding frames (n-1, n-2, …) as well as with its subsequent frames (n+1, n+2, …) – where "nearby" frames have a stronger influence (weight), while "distant" frames have a declining influence. This way, abrupt changes of the gain factor are avoided and, instead, we get smooth transitions of the gain factor over time. Furthermore, since the filter also takes into account future frames, Dynamic Audio Normalizer avoids applying strong gain to "quiet" frames located shortly before "loud" frames. In other words, Dynamic Audio Normalizer adjusts the gain factor early and thus nicely prevents distortions or abrupt gain changes.
One more challenge to consider is that applying the Gaussian smoothing kernel alone can not solve all problems. That's because the smoothing kernel will not only smoothen increasing gain factors but also declining ones! If, for example, a very "loud" frame follows immediately after a sequence of "quiet" frames, the smoothing causes the gain factor to decrease early but slowly. As a result, the filtered gain factor of the "loud" frame could actually turn out to be higher than its (local) maximum gain factor – which results in distortion, if not taken care of! For this reason, the Dynamic Audio Normalizer additionally applies a "minimum" filter, i.e. a filter that replaces each gain factor with the smallest value within the neighborhood. This is done before the Gaussian smoothing kernel in order to ensure that all gain transitions will remain smooth.
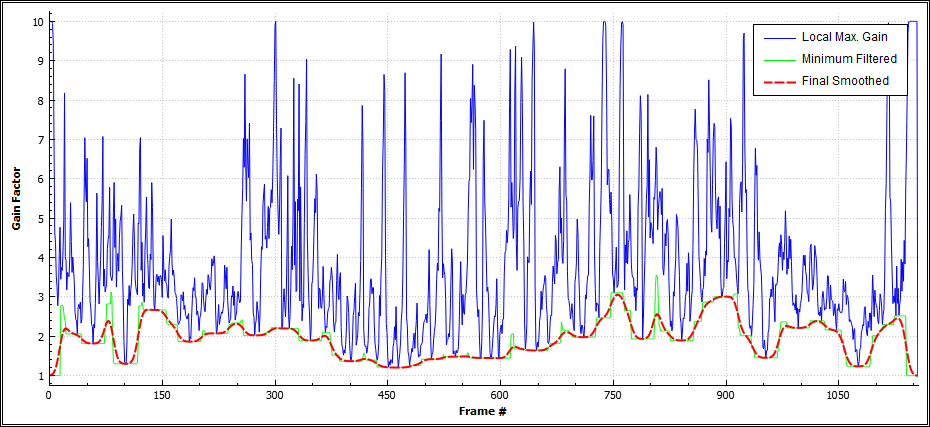
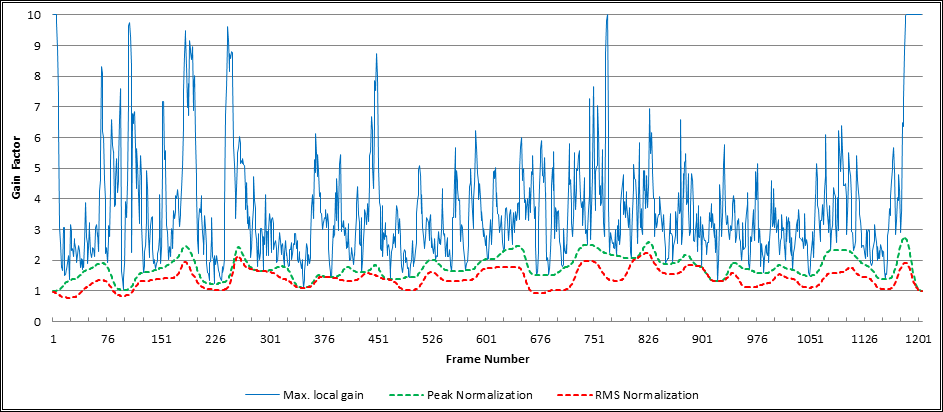
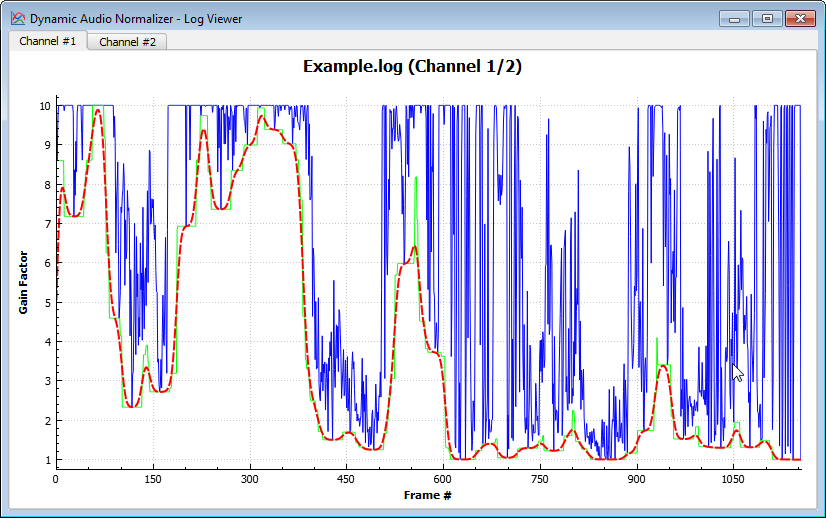
The following example shows the results from a "real world" audio recording that has been processed by the Dynamic Audio Normalizer algorithm. The chart shows the maximum local gain factors for each individual frame (blue) as well as the minimum filtered gain factors (green) and the final smoothened gain factors (orange). Note the very "smooth" progression of the final gain factors. At the same time, the maximum local gain factors are approached as closely as possible. Last but not least note that the smoothened gain factors never exceed the maximum local gain factor, which prevents distortions.
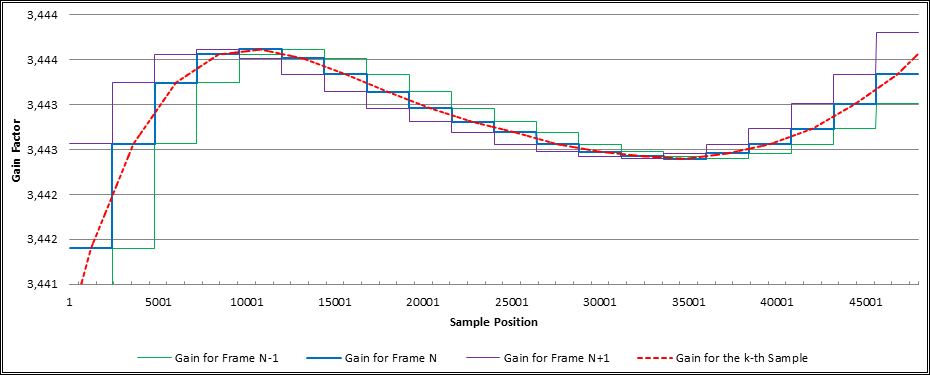
So far it has been discussed how the "optimal" gain factor for each frame is determined. However, since each frame contains a large number of samples – at a typical sampling rate of 44,100 Hz and a standard frame size of 500 milliseconds we have 22,050 samples per frame – it is also required to infer the gain factor for each individual sample within the frame. The most simple approach, of course, would be applying the same gain factor to all samples in a certain frame. But this would also lead to abrupt changes of the gain factor at each frame boundary, while the gain factor remains completely constant within the frames. A better approach, as implemented in the Dynamic Audio Normalizer, is interpolating the per-sample gain factors. In particular, the Dynamic Audio Normalizer applies a straight-forward linear interpolation, which is used to compute the gain factors for the samples of the n-th frame from the gain factors G'[n-1], G'[n] and G'[n+1] – where G'[k] denotes the gain factor of the k-th frame. The following graph shows how the per-sample gain factors (orange) are interpolated from the gain factors of the preceding (G'[n-1], green), current (G'[n], blue) and subsequent (G'[n+1], purple) frame.
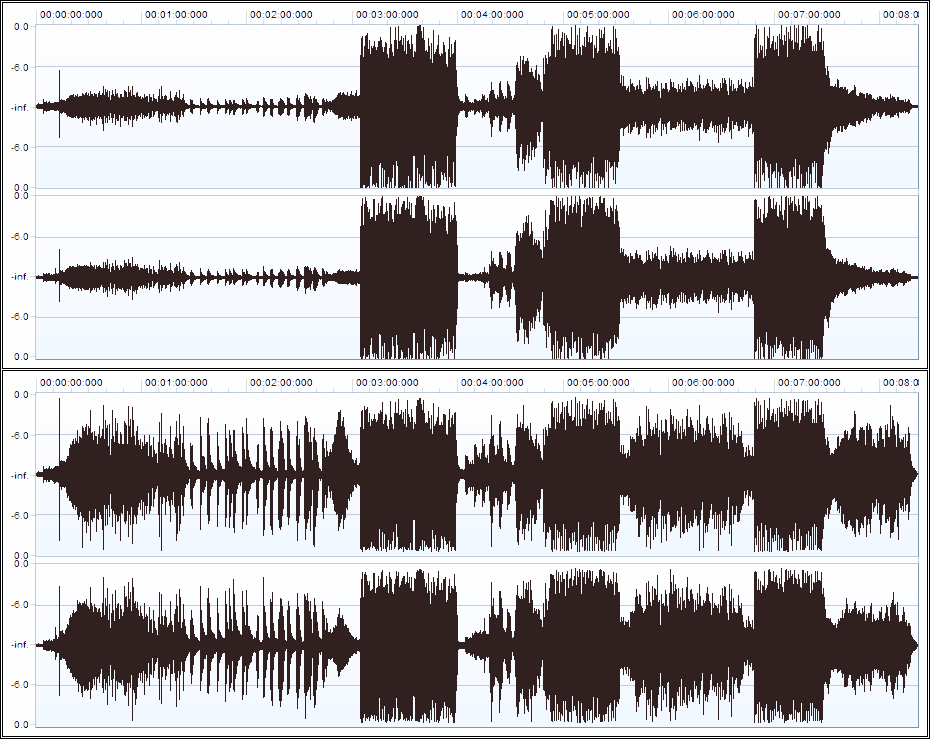
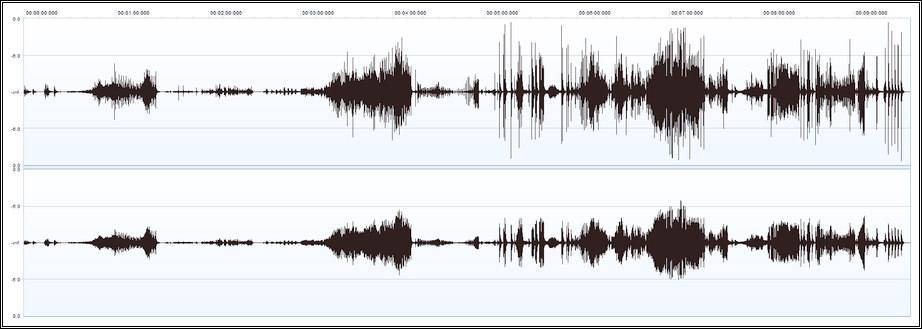
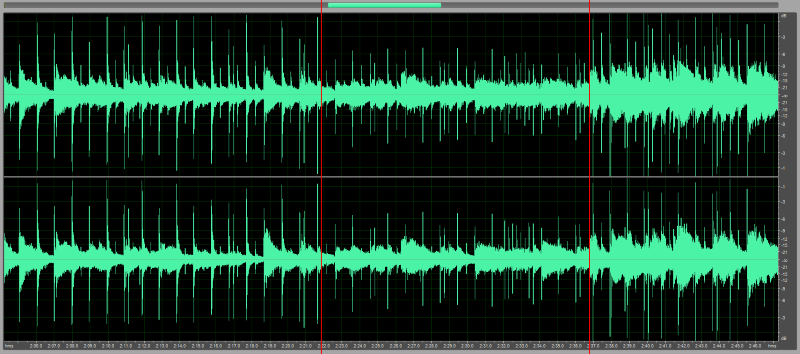
Finally, the following waveform view illustrates how the volume of a "real world" audio recording has been harmonized by the Dynamic Audio Normalizer. The upper graph shows the unprocessed original recording while the lower graph shows the output as created by the Dynamic Audio Normalizer. As can be seen, the significant volume variation between the "loud" and the "quiet" parts that existed in the original recording has been rectified – to a great extent – while the dynamics within each section of the input have been retained. Also, there is absolutely no clipping or distortion in the "loud" sections.
Dynamic Audio Normalizer can be downloaded from one of the following official mirror sites:
Note: Windows binaries are provided in the compressed ZIP format. Simply use 7-Zip or a similar tool to unzip all files to new/empty directory. If in doubt, Windows users should download the "static" version. That's it!
The Dynamic Audio Normalizer "core" library and CLI front-end are written in plain C++11 and therefore do not have any system requirements, except for a conforming C++ compiler. Currently, the Microsoft Visual C++ compiler and the GNU Compiler Collection (GCC) are actively supported. Other compilers should work too, but this cannot be guaranteed.
Pre-compiled binaries are provided for the Windows and GNU/Linux platforms. The 32-Bit Windows binaries should work on Windows XP (with Service Pack 2) or any later version (32-Bit or 64-Bit), while the 64-Bit Windows binaries require the "x64" edition of Windows Vista or any later 64-Bit Windows. Linux binaries are provided for some popular distributions (latest "Long Term Support" version at the time of release). Those Linux binaries may work on other distributions too, or not. Therefore, Linux users are generally recommended to compile the Dynamic Audio Normalizer themselves, from the source codes.
All pre-compiled binaries have been optimized for processors that support at least the SSE2 instruction set, so an SSE2-enabled processor (Pentium 4, Athlon 64, or later) is required. For legacy processors you will need to compile Dynamic Audio Normalizer and all the third-party libraries yourself, from the sources – with appropriate compiler settings.
The Dynamic Audio Normalizer depends on some third-party libraries. Those libraries need to be present at runtime! How to obtain the required third-party libraries, if not already installed, depends on the operating system.
For the Windows platform, the release packages already contain all required third-party libraries. We provide separate Static and DLL packages though. The "Static" binaries have all the required libraries built-in (including third-party libraries and C-Runtime) and thus they do not depend on any separate DLL files. At the same time, the "DLL" package contains separate DLL files for the Dynamic Audio Normalizer "core" library as well as for the required third-party libraries and the C-Runtime. If you don't understand what this means, then simply go with the "Static" version. If you are a programmer and you want to invoke the Dynamic Audio Normalizer "core" library from your own program, then you need to go with the "DLL" version.
For the Linux platform, the release packages do not contain any third-party libraries. That's because, on Linux, it is highly recommended to install those libraries via the package manager. Usually, most of the required third-party libraries will already be installed on your Linux-based system, but some may need to be installed explicitly. The details depend on the particular Linux distribution and on the particular package manager. We give examples for Ubuntu, openSUSE and CentOS here:
Ubuntu 16.04 LTS:
sudo apt install libsndfile1 libmpg123-0 libqtgui4openSUSE Leap 42.2:
sudo zypper addrepo \
http://download.opensuse.org/repositories/multimedia:libs/openSUSE_Leap_42.2/multimedia:libs.repo
sudo zypper refresh
sudo zypper install libsndfile1 libmpg123-0 libqt4-x11CentOS/RHEL 7.3:
sudo yum -y install epel-release
sudo rpm -Uvh http://li.nux.ro/download/nux/dextop/el7/x86_64/nux-dextop-release-0-5.el7.nux.noarch.rpm
sudo yum install libsndfile libmpg123 qt-x11Note: There are some additional indirect dependencies that will be resolved automatically by the package manager.
There is preliminary support for building on Mac OS X:
brew cask install java
brew install python3
brew install libsndfile mpg123
brew install ant pandoc wget
export JAVA_HOME=$(/usr/libexec/java_home)
make MODE=no-guiThe following files are included in the Dynamic Audio Normalizer release package (Windows, "DLL" version):
api-ms-win-* - Microsoft Universal CRT redistributable
DynamicAudioNormalizer.h - Header file for the Dynamic Audio Normalizer library
DynamicAudioNormalizer.pas - Pascal wrapper for the Dynamic Audio Normalizer library
DynamicAudioNormalizerAPI.dll - Dynamic Audio Normalizer core library (shared)
DynamicAudioNormalizerAPI.lib - Import library for the Dynamic Audio Normalizer library
DynamicAudioNormalizerCLI.exe - Dynamic Audio Normalizer command-line application
DynamicAudioNormalizerGUI.exe - Dynamic Audio Normalizer log viewer application
DynamicAudioNormalizerJNI.jar - Java wrapper for the Dynamic Audio Normalizer library
DynamicAudioNormalizerNET.dll - .NET wrapper for the Dynamic Audio Normalizer library
DynamicAudioNormalizerSoX.exe - SoX binary with included Dynamic Audio Normalizer effect
DynamicAudioNormalizerVST.dll - Dynamic Audio Normalizer VST wrapper library
libmpg123.dll - libmpg123 library, used for reading MPEG audio files
libsndfile-1.dll - libsndfile library, used for reading/writing audio files
msvcp140.dll - Visual C++ 2015 runtime library redistributable
pthreadVC2.dll - POSIX threading library, used for thread management
QtCore4.dll - Qt library, used to create the graphical user interfaces
QtGui4.dll - Qt library, used to create the graphical user interfaces
README.html - The README file
ucrtbase.dll - Microsoft Universal CRT redistributable
vcruntime140.dll - Visual C++ 2015 runtime library redistributableNote: Standard binaries are 32-Bit (x86), though 64-Bit (AMD64/EM64T) versions can be found in the x64 sub-folder.
The Dynamic Audio Normalizer standalone program can be invoked via command-line interface (CLI), which can be done either manually from the command prompt or automatically (scripted), e.g. by using a batch file.
The basic Dynamic Audio Normalizer command-line syntax is as follows:
DynamicAudioNormalizerCLI.exe -i <;input_file> -o <output_file> [options]Note that the input file (option -i or --input) and the output file (option -o or --output) always have to be specified, while all other parameters are optional. But take care, an existing output file will be overwritten silently!
Also note that the Dynamic Audio Normalizer uses libsndfile for input/output, so a wide range of file formats (WAV, W64, FLAC, Ogg/Vorbis, AIFF, AU/SND, etc) as well as various sample types (ranging from 8-Bit INT to 64-Bit FP) are supported. However, libsndfile can not read MP2 (MPEG Audio Layer II) or MP3 (MPEG Audio Layer III) files, so libmpg123 will be used for reading files that "look" like MP2 or MP3 data. You can specify -d option to select the desired decoder library explicitly.
By default, the Dynamic Audio Normalizer program will guess the output file format from the file extension of the specified output file. This can be overwritten by using the -t option. To create a FLAC file, e.g., you can specify -t flac.
Passing "raw" PCM data via pipe is supported. Specify the file name "-" in order to read from or write to the stdin or stdout, respectively. When reading from the stdin, you have to specify the input sample format, channel count and sampling rate!
For a list of all available options, see the list below or run DynamicAudioNormalizerCLI.exe --help from the command prompt. Also, refer to the configuration chapter for more details on the Dynamic Audio Normalizer parameters!
The following Dynamic Audio Normalizer command-line options are available:
Input/Output:
-i --input <file> Input audio file [required]
-d --input-lib <value> Input decoder library [default: auto-detect]
-o --output <file> Output audio file [required]
-t --output-fmt <value> Output format [default: auto-detect]Algorithm Tweaks:
-f --frame-len <value> Frame length, in milliseconds [default: 500]
-g --gauss-size <value> Gauss filter size, in frames [default: 31]
-p --peak <value> Target peak magnitude, 0.1-1 [default: 0.95]
-m --max-gain <value> Maximum gain factor [default: 10.00]
-r --target-rms <value> Target RMS value [default: 0.00]
-n --no-coupling Disable channel coupling [default: on]
-c --correct-dc Enable the DC bias correction [default: off]
-b --alt-boundary Use alternative boundary mode [default: off]
-s --compress <value> Compress the input data [default: 0.00]Diagnostics:
-v --verbose Output additional diagnostic info
-l --log-file <file> Create a log file
-h --help Print *this* help screenRaw Data Options:
--input-bits <value> Bits per sample, e.g. '16' or '32'
--input-chan <value> Number of channels, e.g. '2' for Stereo
--input-rate <value> Sample rate in Hertz, e.g. '44100'Here are some examples on how to invoke the Dynamic Audio Normalizer command-line program:
Read input from Wave file and write output to a Wave file again:
DynamicAudioNormalizerCLI.exe -i "in_original.wav" -o "out_normalized.wav"Read input from stdin (input is provided by FFmpeg via pipe) and write output to Wave file:
ffmpeg.exe -i "movie.mkv" -loglevel quiet -vn -f s16le -c:a pcm_s16le - |
DynamicAudioNormalizerCLI.exe -i - --input-bits 16 --input-chan 2 --input-rate 48000 -o "output.wav"Read input from Wave file and write output to stdout (output is passed to FFmpeg via pipe):
DynamicAudioNormalizerCLI.exe -i "input.wav" -o - |
ffmpeg.exe -loglevel quiet -f s16le -ar 44100 -ac 2 -i - -c:a libmp3lame -qscale:a 2 "output.mp3"The Dynamic Audio Normalizer library is integrated in the SoX and FFmpeg command-line applications!
As an alternative to the Dynamic Audio Normalizer command-line front-end, the Dynamic Audio Normalizer library may also be used as an effect in SoX (Sound eXchange), a versatile audio editor and converter.
Note, however, that standard SoX distributions do not currently support the Dynamic Audio Normalizer. Instead, a special patched build of SoX that has the Dynamic Audio Normalizer effect enabled is required!
When using SoX, the Dynamic Audio Normalizer can be invoked by adding the "dynaudnorm" effect to your chain:
DynamicAudioNormalizerSoX.exe -S "in_original.wav" -o "out_normalized.wav" dynaudnorm [options]For details about the SoX command-line syntax, please refer to the offical SoX documentation, or simply type --help-effect dynaudnorm in order to make SoX print a list of available options.
Furthermore, the Dynamic Audio Normalizer is available as an audio filter in FFmpeg, a complete, cross-platform solution to record, convert and stream audio and video. Thanks to Paul B Mahol for porting Dynamic Audio Normalizer to FFmpeg.
Since the Dynamic Audio Normalizer has been committed to the official FFmpeg codebase, you can use any FFmpeg binary. Just be sure to grab an up-to-date FFmpeg that has the "dynaudnorm" filter integrated. Windows users can download ready-made FFmpeg binaries here. Linux users install FFmpeg from the package manager of their distribution or build it themselves. If the FFmpeg included with your distribution is too old, find recent Linux binaries here.
When using FFmpeg, the Dynamic Audio Normalizer can be invoked by adding the "dynaudnorm" filter via -af switch:
ffmpeg.exe -i "in_original.wav" -af dynaudnorm "out_normalized.wav"For details about the FFmpeg command-line syntax, please refer to the FFmpeg documentation, see the FFmpeg filtering guide, or type ffmpeg.exe -h full | more for a list of available options.
VST PlugIn Interface Technology by Steinberg Media Technologies GmbH. VST is a trademark of Steinberg Media Technologies GmbH.

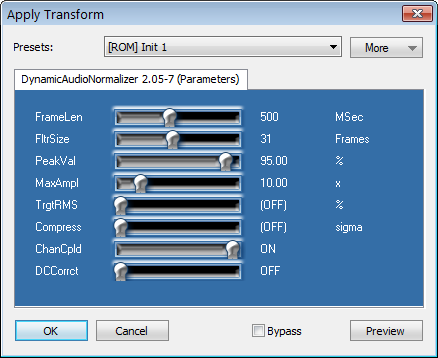
The Dynamic Audio Normalizer is also available in the form of a VST (Virtual Studio Technology) plug-in. The VST plug-in interface technology, developed by Steinberg Media Technologies, provides a way of integrating arbitrary audio effects (and instruments) into arbitrary applications – provided that the audio effect is available in the form of a VST plug-in and provided that the application supports "hosting" VST plug-ins. An application capable of loading and using VST plug-ins is referred to as a VST host. This means that the Dynamic Audio Normalizer can be used as an effect in any VST host. Note that VST is widely supported in DAWs (Digital Audio Workstations) nowadays, including most of the popular Wave Editors. Therefore, the provided Dynamic Audio Normalizer VST plug-in can be integrated into all of these applications easily. Note that most VST hosts provide a graphical user interface to configure the VST plug-in. The screen capture below shows the Dynamic Audio Normalizer as it appears in the Acoustica software by Acon AS. The options exposed by the VST plug-in are identical to those exposed by the CLI version.
The exact steps that are required to load, activate and configure a VST plug-in differ from application to application. However, it will generally be required to make the application "recognize" the new VST plug-in, i.e. DynamicAudioNormalizerVST.dll first. Most applications will either pick up the VST plug-in from the global VST directory – usually located at C:\Program Files (x86)\Steinberg\Vstplugins on Windows – or provide an option to choose the directory from where to load the VST plug-in. This means that, depending on the individual application, you will either need to copy the Dynamic Audio Normalizer VST plug-in into the global VST directory or tell the application where the Dynamic Audio Normalizer VST plug-in is located. Note that, with some applications, it may also be required to explicitly scan for new VST pluig-ins. See the manual for details! The screen capture bellow shows the situation in the Acoustica 6.0 software by Acon AS. Here we simply open the "VST Directories" dialogue from the "Plug-Ins" menu, then add the Dynamic Audio Normalizer directory and finally click "OK".

Furthermore, note that – unless you are using the static build of the Dynamic Audio Normalizer – the VST plug-in DLL, i.e. DynamicAudioNormalizerVST.dll, also requires the Dynamic Audio Normalizer core library, i.e. DynamicAudioNormalizerAPI.dll. This means that the core library must be made available to the VST host in addition to the VST plug-in itself. Otherwise, loading the VST plug-in DLL is going to fail! Copying the core library to the same directory, where the VST plug-in DLL, is located generally is not sufficient. Instead, the core library must be located in one of those directories that are checked for additional DLL dependencies (see here for details). Therefore, it is recommended to copy the DynamicAudioNormalizerAPI.dll file into the same directory where the VST host's "main" executable (EXE file) is located.
Important: Please note that Dynamic Audio Normalizer VST plug-in uses the VST interface version 2.x, which is the most widely supported VST version at this time. VST interface version 3.x is not currently used, supported or required. Also note that 32-Bit (x86) VST host application can only work with 32-Bit VST plug-ins and, similarly, 64-Bit (AMD64/Intel64) VST host application can only work with 64-Bit VST plug-ins. Depending on the "bitness" of your individual VST host application, always the suitable VST plug-in DLL file, 32- or 64-Bit, must be chosen!
The algorithm used by the Dynamic Audio Normalizer uses a "look ahead" buffer. This necessarily requires that – at the beginning of the process – we read a certain minimum number of input samples before the first output samples can be computed. With a more flexible effect interface, like the one used by SoX, the plug-in could request as many input samples from the host application as required, before it starts returning output samples. The VST interface, however, is rather limited in this regard: VST enforces that the plug-in process the audio in small chunks. The size of these chunks is dictated by the host application. Furthermore, VST enforces that the plug-in returns the corresponding output samples for each chunk of audio data immediately – the VST host won't provide the next chunk of input samples until the VST plug-in has returned the output samples for the previous chunk. To the best of our knowledge, there is no way to request even more input samples from the VST host! Consequently, the only known way to realize a "look ahead" buffer with VST is actually delaying all audio samples and returning some "silent" samples at the beginning.
At least, VST provides the VST plug-in with a method to report its delay to the VST host application. Unfortunately, to the best of our knowledge, the VST specification lacks a detailed description on how a host application is required to deal with such a delay. This means that the actual behavior totally depends on the individual host application! Anyway, it is clear that, if a VST plug-in reports a delay of N samples, an audio editor shall discard the first N samples returned by that plug-in. Also, the audio editor shall feed N samples of additional "dummy" data to the plug-in at the very end of the process – in order to flush the pending output samples. In practice, however, it turns out that, while some audio editors show the "correct" behavior, others do not. Those audio editors seem to ignore the plug-in's delay, so the audio file will end up shifted and truncated!
The Dynamic Audio Normalizer VST plug-in does report its delay to the VST host application. Thus, if you encounter shifted and/or truncated audio after the processing, this means that there is a bug in the VST host application. And, sadly, the plug-in can do absolutely nothing about this. Below, there is a non-exhaustive list of audio editors with proper VST support. Those have been tested to work correctly. There also is a list of audio editors with known problems. Those should not be used for VST processing, until the respective developers have fixed the issue…
Incomplete list of VST hosts that have been tested to work correctly with the Dynamic Audio Normalizer VST plug-in:
Disclaimer: There is absolutely no guarantee for the completeness or correctness of the above information!
List of VST hosts with known problems that do not work correctly with VST plug-ins like the Dynamic Audio Normalizer:
Disclaimer: There is absolutely no guarantee for the completeness or correctness of the above information!
If you are the developer of one of the "problematic" tools and you are interested in fixing the problem in your product, or if you have already fixed the problem in the meantime, then please let us know, so that we can update the information…
The Dynamic Audio Normalizer is also available in the form of a DSP/Effect plug-in for Winamp, the popular media player created by Nullsoft. This way, the Dynamic Audio Normalizer can be applied to your audio files during playback, in real-time.
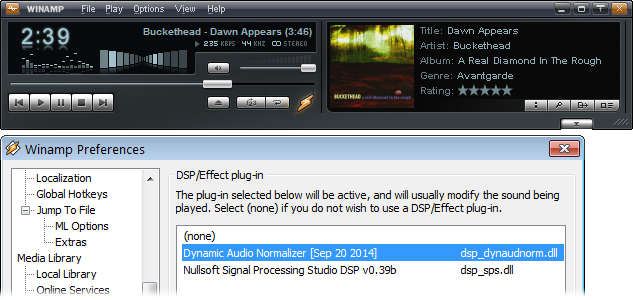
If you have not installed the latest version of Winamp yet, please update your Winamp installation first. Although the development of Winamp seems to be discontinued and its future remains uncertain at this point, you can still download the last Winamp release (as of January 2017), which is Winamp 5.666 "Redux", from one of the following download mirrors:
Be sure to grab the patched (aka "Redux") edition of Winamp 5.666, which has some security issues fixed and some defunct "online" features removed. Older versions are generally not recommended and may not work with the plug-in! Once the latest version of Winamp 5.x is installed, simply copy the provided Winamp plug-in file DynamicAudioNormalizerWA5.dll into the directory for Winamp DSP/Effect plug-ins. By default, that is the sub-directory Plugins inside your Winamp installation directory. So, if Winamp was installed at C:\Program Files (x86)\Winamp, the default plug-in directory would be C:\Program Files (x86)\Winamp\Plugins. If you have installed Winamp to a different directory or if you have changed the plug-in directory to a different location (see the Winamp "Perferences" dialogue), then please adjust the path accordingly!
Note that copying the plug-in DLL into the Plugins directory may require administrative privileges. That's because C:\Program Files (x86) is a protected system directory. Also note that the plug-in DLL must be renamed to dsp_dynaudnorm.dll in order to make Winmap recognize the DLL. Any other file name of your choice will work just as well, as long as it starts with the dsp_ prefix. Once the plug-in DLL file is located at the correct place, e.g. C:\Program Files (x86)\Winamp\Plugins\dsp_dynaudnorm.dll, it should appear in the Winamp "Preferences" dialogue after the next restart. More specifically, you should find the "Dynamic Audio Normalizer" plug-in on the "Plug-ins" → "DSP/Effect" page. Simply select the desired plug-in from the list of available DSP/Effect plug-ins and it will be active from now on.
Furthermore, note that – unless you are using the static build of the Dynamic Audio Normalizer – the Winamp plug-in DLL also requires the Dynamic Audio Normalizer core library, i.e. DynamicAudioNormalizerAPI.dll. This means that the core library must be made available to Winamp in addition to the DSP/Effect plug-in itself. Otherwise, loading the DSP/Effect plug-in DLL is going to fail! Though, copying the core library to the same directory, where the plug-in DLL is located, i.e. the Plugins directory, generally is not sufficient. Instead, the core library must be located in one of those directories that are checked for additional DLL dependencies (see here for details). Therefore, it is recommended to copy the DynamicAudioNormalizerAPI.dll file into the same directory where the Winamp "main" executable (EXE file) is located.
The Dynamic Audio Normalizer plug-in for Winamp does not currently provide a configuration dialogue. However, the most important settings are stored in the Windows registry and can be edited using the Registry Editor (regedit.exe):
The settings are stored under the following key:
HKEY_CURRENT_USER\Software\MuldeR\DynAudNorm\WA5The following reg-values are currently supported:
FilterSize: Controlls the Gaussian filter window size, in frames (DWORD)
FrameLenMsec: Controlls the frame length, in milliseconds (DWORD)
Note: If any of the registry values do not exist yet, simply create them. Restart Winamp to make your changes take effect!
Unfortunately, the programming interface (API) that Winamp offers to DSP/Effect plug-in is very limited. In particular, Winamp does not report to the plug-in when playback starts or stops, it does not report to the plug-in when switching to another track, and it does not report to the plug-in when seeking within the current track. Also, in none of the aforementioned situations Winamp is going to re-initialize the plug-in. Instead, Winamp just feeds the plug-in with an "unbroken" stream of audio samples – even when the user seeks to a different position in the current track or switches to a completely different track.
Consequently, it is not technically possible for the plug-in to "flush" its internal buffer in the relevant situations! As a result, users will experience a delay of approximately 15 seconds when the Dynamic Audio Normalizer plug-in for Winamp is active. If, for example, you move the slider on Winamp's seek bar, it will take about 15 seconds until you actually hear the audio from the new position. Similarly, if you switch to another track, it will take about 15 seconds until you actually hear the audio from the new track. To make it clear again: Only the Winamp developers could fix this annoyance – by providing DSP/Effect plug-in developers with a more suitable API. However, given the current state of Winamp development, this is unlikely to happen.
This chapter describes the configuration options that can be used to tweak the behavior of the Dynamic Audio Normalizer.
While the default parameter of the Dynamic Audio Normalizer have been chosen to give satisfying results for a wide range of audio sources, it can be advantageous to adapt the parameters to the individual audio file as well as to your personal preferences. The default settings have been chosen rather "conservative", so that the dynamics of the audio are preserved well. People who desire a more "aggressive" effect should try using a smaller filter size, or enable input compression.
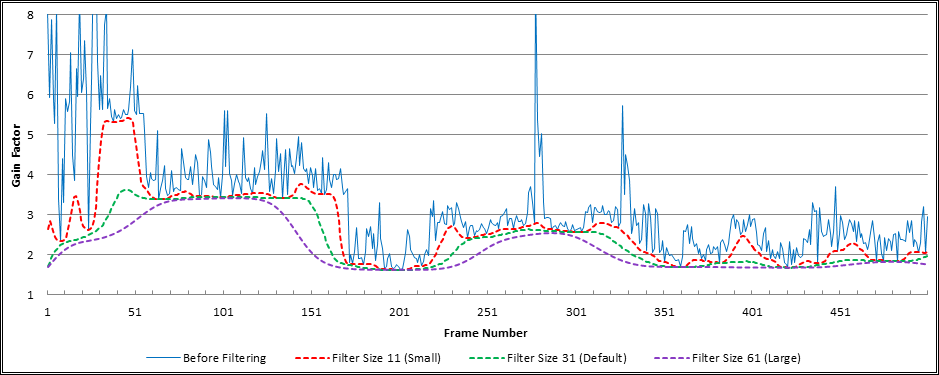
Probably the most important parameter of the Dynamic Audio Normalizer is the "window size" of the Gaussian smoothing filter. It can be controlled with the --gauss-size option. The filter's window size is specified in frames, centered around the current frame. For the sake of simplicity, this must be an odd number. Consequently, the default value of 31 takes into account the current frame, as well as the 15 preceding frames and the 15 subsequent frames. Using a larger Gaussian window size results in a stronger smoothing effect and thus in less gain variation, i.e. slower gain adaptation. Conversely, using a smaller Gaussian window size results in a weaker smoothing effect and thus in more gain variation, i.e. faster gain adaptation. In other words, the more you increase this value, the more the Dynamic Audio Normalizer will behave like a "traditional" (non-dynamic) normalization filter. On the contrary, the more you decrease this value, the more "aggressively" the Dynamic Audio Normalizer will behave, i.e. more like a dynamic range compressor. The following graph illustrates the effect of different Gaussian window sizes – 11 (orange), 31 (green), and 61 (purple) frames – on the progression of the final filtered gain factor.
The target peak magnitude specifies the highest permissible magnitude level for the normalized audio file. It is controlled by the --peak option. Since the Dynamic Audio Normalizer represents audio samples as floating point values in the -1.0 to 1.0 range – regardless of the input and output audio format – this value must be in the 0.0 to 1.0 range. Consequently, the value 1.0 is equal to 0 dBFS, i.e. the maximum possible digital signal level (± 32767 in a 16-Bit file). The Dynamic Audio Normalizer will try to approach the target peak magnitude as closely as possible, but at the same time it also makes sure that the normalized signal will never exceed the peak magnitude. A frame's maximum local gain factor is imposed directly by the target peak magnitude. The default value is 0.95 and thus leaves a headroom of 5%. It is not recommended to go above this value!
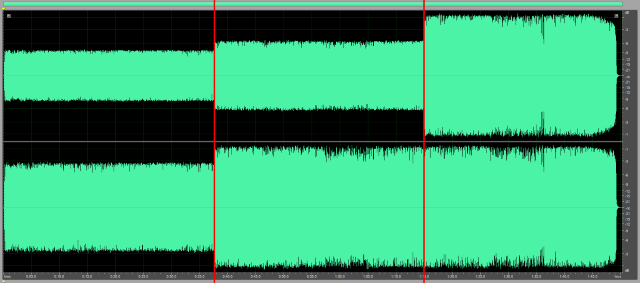
By default, the Dynamic Audio Normalizer will amplify all channels by the same amount. This means the same gain factor will be applied to all channels, i.e. the maximum possible gain factor is determined by the "loudest" channel. In particular, the highest magnitude sample for the n-th frame is defined as S_max[n]=Max(s_max[n][1],s_max[n][2],…,s_max[n][C]), where s_max[n][k] denotes the highest magnitude sample in the k-th channel and C is the channel count. The gain factor for all channels is then derived from S_max[n]. This is referred to as channel coupling and for most audio files it gives the desired result. Therefore, channel coupling is enabled by default. However, in some recordings, it may happen that the volume of the different channels is uneven, e.g. one channel may be "quieter" than the other one(s). In this case, the --no-coupling option can be used to disable the channel coupling. This way, the gain factor will be determined independently for each channel k, depending only on the individual channel's highest magnitude sample s_max[n][k]. This allows for harmonizing the volume of the different channels. The following wave view illustrates the effect of channel coupling: It shows an input file with uneven channel volumes (left), the same file after normalization with channel coupling enabled (center) and again after normalization with channel coupling disabled (right).
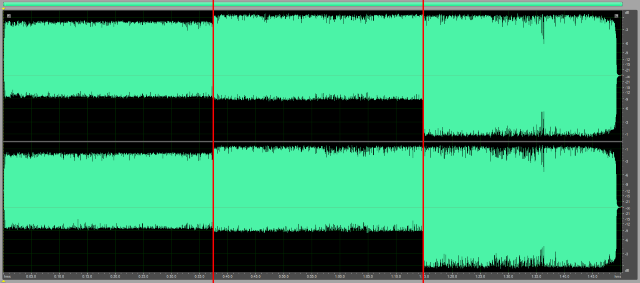
An audio signal (in the time domain) is a sequence of sample values. In the Dynamic Audio Normalizer these sample values are represented in the -1.0 to 1.0 range, regardless of the original input format. Normally, the audio signal, or "waveform", should be centered around the zero point. That means if we calculate the mean value of all samples in a file, or in a single frame, then the result should be 0.0 or at least very close to that value. If, however, there is a significant deviation of the mean value from 0.0, in either positive or negative direction, this is referred to as a DC bias or DC offset. Since a DC bias is clearly undesirable, the Dynamic Audio Normalizer provides optional DC bias correction, which can be enabled using the --correct-dc switch. With DC bias correction enabled, the Dynamic Audio Normalizer will determine the mean value, or "DC correction" offset, of each input frame and subtract that value from all of the frame's sample values – which ensures those samples are centered around 0.0 again. Also, in order to avoid "gaps" at the frame boundaries, the DC correction offset values will be interpolated smoothly between neighbouring frames. The following wave view illustrates the effect of DC bias correction: It shows an input file with positive DC bias (left), the same file after normalization with DC bias correction disabled (center) and again after normalization with DC bias correction enabled (right).
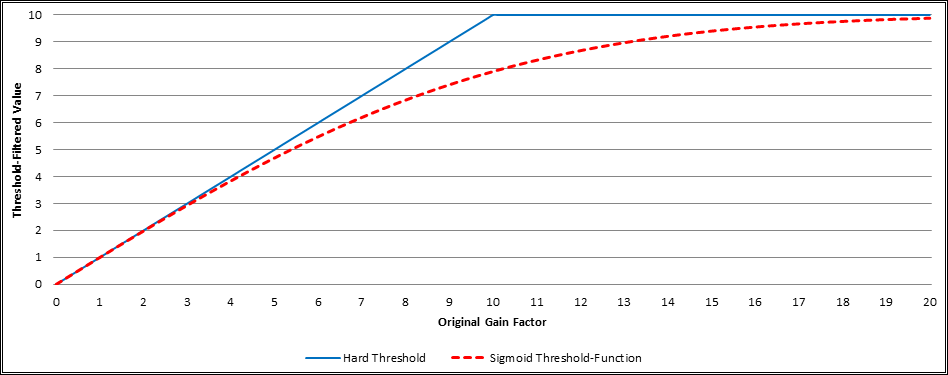
The Dynamic Audio Normalizer determines the maximum possible (local) gain factor for each input frame, i.e. the maximum gain factor that does not result in clipping or distortion. The maximum gain factor is determined by the frame's highest magnitude sample. However, the Dynamic Audio Normalizer additionally bounds the frame's maximum gain factor by a predetermined (global) maximum gain factor. This is done in order to avoid "extreme" gain factors in silent, or almost silent, frames. By default, the maximum gain factor is 10.0, but it can be adjusted using the --max-gain switch. For most input files the default value should be sufficient, and it usually is not recommended to increase this value above the default. Though, for input files with a rather low overall volume level, it may be necessary to allow even higher gain factors. Be aware, however, that the Dynamic Audio Normalizer does not simply apply a "hard" threshold (i.e. it does not simply cut off values above the threshold). Instead, a "sigmoid" thresholding function will be applied on the final gain factors, as depicted in the following chart. This way, the gain factors will smoothly approach the threshold value, but they will never exceed that value.
By default, the Dynamic Audio Normalizer performs "peak" normalization. This means that the maximum local gain factor for each frame is defined (only) by the frame's highest magnitude sample (the "loudest" peak). This way, the samples can be amplified as much as possible without exceeding the maximum signal level, i.e. without clipping. Optionally, however, the Dynamic Audio Normalizer can also take into account the frame's root mean square, or, in short, RMS. In electrical engineering, the RMS is commonly used to determine the power of a time-varying signal. It is therefore considered that the RMS is a better approximation of the "perceived loudness" than just looking at the signal's peak magnitude. Consequently, by adjusting all frames to a constant RMS value, a uniform "perceived loudness" can be established. With the Dynamic Audio Normalizer, RMS processing can be enabled using the --target-rms switch. This specifies the desired RMS value, in the 0.0 to 1.0 range. There is no default value, because RMS processing is disabled by default. If a target RMS value has been specified, a frame's local gain factor is defined as the factor that would result in exactly that RMS value. Note, however, that the maximum local gain factor is still restricted by the frame's highest magnitude sample, in order to prevent clipping. The following chart shows the same file normalized without (green) and with (orange) RMS processing enabled.
The Dynamic Audio Normalizer processes the input audio in small chunks, referred to as frames. This is required, because a peak magnitude has no meaning for just a single sample value. Instead, we need to determine the peak magnitude for a contiguous sequence of sample values. While a "standard" normalizer would simply use the peak magnitude of the complete file, the Dynamic Audio Normalizer determines the peak magnitude individually for each frame. The length of a frame is specified in milliseconds. By default, the Dynamic Audio Normalizer uses a frame length of 500 milliseconds, which has been found to give good results with most files, but it can be adjusted using the --frame-len switch. Note that the exact frame length, in number of samples, will be determined automatically, based on the sampling rate of the individual input audio file.
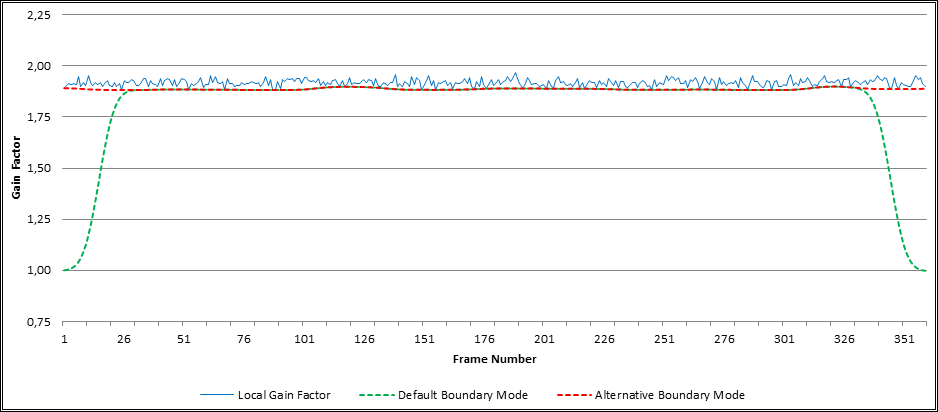
As explained before, the Dynamic Audio Normalizer takes into account a certain neighbourhood around each frame. This includes the preceding frames as well as the subsequent frames. However, for the "boundary" frames, located at the very beginning and at the very end of the audio file, not all neighbouring frames are available. In particular, for the first few frames in the audio file, the preceding frames are not known. And, similarly, for the last few frames in the audio file, the subsequent frames are not known. Thus, the question arises which gain factors should be assumed for the missing frames in the "boundary" region. The Dynamic Audio Normalizer implements two modes to deal with this situation. The default boundary mode assumes a gain factor of exactly 1.0 for the missing frames, resulting in a smooth "fade in" and "fade out" at the beginning and at the end of the file, respectively. The alternative boundary mode can be enabled by using the --alt-boundary switch. The latter mode assumes that the missing frames at the beginning of the file have the same gain factor as the very first available frame. It furthermore assumes that the missing frames at the end of the file have same gain factor as the very last frame. The following chart illustrates the difference between the default (green) and the alternative (red) boundary mode. Note hat, for simplicity's sake, a file containing constant volume white noise was used as input here.
By default, the Dynamic Audio Normalizer does not apply "traditional" compression. This means that signal peaks will not be pruned and thus the full dynamic range will be retained within each local neighbourhood. However, in some cases it may be desirable to combine the Dynamic Audio Normalizer's normalization algorithm with a more "traditional" compression. For this purpose, the Dynamic Audio Normalizer provides an optional compression (thresholding) function. It is disabled by default and can be enabled by using the --compress switch. If (and only if) the compression feature is enabled, all input frames will be processed by a soft knee thresholding function prior to the actual normalization process. Put simply, the thresholding function is going to prune all samples whose magnitude exceeds a certain threshold value. However, the Dynamic Audio Normalizer does not simply apply a fixed threshold value. Instead, the threshold value will be adjusted for each individual frame. More specifically, the threshold for a specific input frame is defined as T = μ + (c · σ), where μ is the mean of all sample magnitudes in the current frame, σ is the standard deviation of those sample magnitudes and c is the parameter controlled by the user. Note that, assuming the samples magnitudes are following (roughly) a normal distribution, about 68% of the sample values will be within the μ ± σ range, about 95% of the sample values will be within the μ ± 2σ range and more than 99% of the sample values will be within the μ ± 3σ range. Consequently, a parameter of c = 2 will prune about 5% of the frame's highest magnitude samples, a parameter of c = 3 will prune about 1% of the frame's highest magnitude samples, and so on. In general, smaller parameters result in stronger compression, and vice versa. Values below 3.0 are not recommended, because audible distortion may appear! The following waveform view illustrates the effect of the input compression feature: It shows the same input file before (upper view) and after (lower view) the thresholding function has been applied. Please note that, for the sake of clarity, the actual normalization process has been disabled in the following chart. Under normal circumstances, the normalization process is applied immediately after the thresholding function.
Optionally, the Dynamic Audio Normalizer can create a log file. The log file name is specified using the --log-file option. If that option is not used, then no log file will be written. The log file uses a simple text format. The file starts with a header, followed by a list of gain factors. In that list, there is one line per frame. In each line, the first column contains the maximum local gain factor, the second column contains the minimum filtered gain factor, and the third column contains the final smoothed gain factor. This sequence is repeated once per channel.
DynamicAudioNormalizer Logfile v2.00-5
CHANNEL_COUNT:2
10.00000 8.59652 5.07585 10.00000 8.59652 5.07585
8.59652 8.59652 5.64167 8.59652 8.59652 5.64167
9.51783 8.59652 6.17045 9.51783 8.59652 6.17045
...The log file can be displayed as a graphical chart using, for example, the Log Viewer application (DynamicAudioNormalizerGUI) that is included with the Dynamic Audio Normalizer:
This chapter describes the MDynamicAudioNormalizer application programming interface (API). The API specified in this document allows software developer to call the Dynamic Audio Normalizer library from their own programs.
The Dynamic Audio Normalizer "core" library is written in C++. Therefore the native application programming interface (API) is provided in the form of a C++ class. Furthermore, language bindings for the Microsoft.NET platform (C#, VB.NET, etc.) as well as for Java (JRE 1.7 or later), Python (CPython 3.0 or later) and Object Pascal (Delphi 7.0 or later) are provided. For each of these languages, a suitable "wrapper" is provided, which exposes – to the greatest extend possible – the same functions as the native C++ class. Calls to the language-specific wrapper will be forwarded, internally, to the corresponding native method of to the underlying C++ class. Native library calls are handled transparently by the individual language wrapper, so that application developers do not need to worry about interoperability issues. In particular, the language wrapper will take care of data marshalling as well as the management of the native MDynamicAudioNormalizer instances.
C++ applications shall use the native MDynamicAudioNormalizer C++ class directly, which is declared in the DynamicAudioNormalizerAPI.h header file. It is implemented by the shared library DynamicAudioNormalizerAPI.dll (Windows) or libDynamicAudioNormalizerAPI-X.so (Linux). A detailed description of the C++ class is given below.
Note: On the Windows platform, you will need to link your binary against the import library DynamicAudioNormalizerAPI.lib.
C applications can use the C99 "wrapper" functions, which are also declared in the DynamicAudioNormalizerAPI.h header file. Those "wrapper" functions are implemented by the shared library DynamicAudioNormalizerAPI.dll (Windows) or libDynamicAudioNormalizerAPI-X.so (Linux), just like the native C++ interface. There exists a corresponding C99 "wrapper" function for each method of the native C++ class. The "wrapper" functions provide the same functionality and take the same parameters as the underlying C++ methods, except that an additional handle parameter needs to be passed to each "wrapper" function. The handle corresponds to the "this" pointer that is implicitly passed to C++ methods. The C-only functions createInstance() and destroyInstance() correspond to the C++ class' constructor and destructor, respectively.
Note: On the Windows platform, you will need to link your binary against the import library DynamicAudioNormalizerAPI.lib.
Microsoft.NET (C#, VB.NET, etc.) applications can use the DynamicAudioNormalizerNET C++/CLI "wrapper" class, which is implemented by the DynamicAudioNormalizerNET.dll assembly. There exists an equivalent method in the C++/CLI "wrapper" class for each method of the native C++ class. Note, however, that the DynamicAudioNormalizerNET.dll assembly is really just a thin "wrapper" and it requires the native "core" library DynamicAudioNormalizerAPI.dll at runtime!
Java applications can use the JDynamicAudioNormalizer JNI "wrapper" class, which is implemented by the DynamicAudioNormalizerJNI.jar library. There exists an equivalent method in the JNI "wrapper" class for each method of the native C++ class. Note, however, that the DynamicAudioNormalizerJNI.jar JNI "wrapper" requires the native "core" library DynamicAudioNormalizerAPI.dll (Windows) or libDynamicAudioNormalizerAPI-X.so (Linux) at runtime!
Python applications can use our C extension for CPython, which is implemented by the DynamicAudioNormalizerAPI.pyd library. We also provide the PyDynamicAudioNormalizer Python "wrapper" class for convenience, which is declared in the DynamicAudioNormalizer.py module. There exists an equivalent method in the Python "wrapper" class for each method of the native C++ class. Note, however, that the DynamicAudioNormalizerJNI.pyd C extension module requires the native "core" library DynamicAudioNormalizerAPI.dll (Windows) or libDynamicAudioNormalizerAPI-X.so (Linux) at runtime!
Object Pascal (Delphi) applications can use the TDynamicAudioNormalizer Object Pascal "wrapper" class, which is implemented by the DynamicAudioNormalizer.pas unit file. There exists an equivalent method in the Object Pascal "wrapper" class for each method of the native C++ class. Note, however, that the DynamicAudioNormalizer.pas Object Pascal "wrapper" is built on top of the C99 API and it requires the native library DynamicAudioNormalizerAPI.dll at runtime!
All methods of the MDynamicAudioNormalizer class are reentrant, but not thread-safe! Hence, it is safe to use the MDynamicAudioNormalizer class in multi-threaded applications, but only as long as each thread uses its "own" separate MDynamicAudioNormalizer instance. In other words, it is strictly forbidden to call the same MDynamicAudioNormalizer instance concurrently from different threads. But it is admissible to call distinct MDynamicAudioNormalizer instances concurrently from different threads – provided that each thread will access only its "own" instance. If the same MDynamicAudioNormalizer instance needs to be accessed by different threads, then the calling application is responsible for serializing each and every call to that instance, e.g. by means of a Mutex; otherwise undefined behavior follows!
There is one notable exception from the above restrictions: The static methods of the MDynamicAudioNormalizer class as well as the createInstance() function of the "C99" API are perfectly thread-safe. No synchronization is needed for those.
The following listing summarizes the steps that an application needs to follow when using the API:
initialize() method, once, in order to initialize the MDynamicAudioNormalizer instance.processInplace() method, in a loop, until all input samples have been processed. getInternalDelay() for details.flushBuffer() method, in a loop, until all the pending "delayed" output samples have been flushed.Note: The Dynamic Audio Normalizer library processes audio samples, but it does not provide any audio I/O capabilities. Reading or writing the audio samples from or to an audio file is up to the application. A library like libsndfile is helpful!
MDynamicAudioNormalizer(
const uint32_t channels,
const uint32_t sampleRate,
const uint32_t frameLenMsec,
const uint32_t filterSize,
const double peakValue,
const double maxAmplification,
const double targetRms,
const bool channelsCoupled,
const bool enableDCCorrection,
const bool altBoundaryMode,
FILE *const logFile
);Constructor. Creates a new MDynamicAudioNormalizer instance and sets up the normalization parameters.
Parameters:
virtual ~MDynamicAudioNormalizer(void);Destructor. Destroys the MDynamicAudioNormalizer instance and releases all memory that it occupied.
bool initialize(void);Initializes the MDynamicAudioNormalizer instance. Validates the parameters and allocates the required memory buffers.
This function must be called once for each new MDynamicAudioNormalizer instance. It must be called *before the processInplace() function can be called for the first time. Do not call processInplace(), if this function has failed!
Return value:
true if everything was successful or false if something went wrong.bool process(
const double **samplesIn,
double **samplesOut,
int64_t inputSize,
int64_t &outputSize
);This is the "main" processing function. It shall be called in a loop until all input audio samples have been processed.
The function works "out-of-place": It reads the original input samples from the specified samplesIn buffer and then writes the normalized output samples, if any, back into the samplesOut buffer. The content of samplesIn will be preserved.
Note: A call to this function reads all provided input samples from the buffer, but the number of output samples that are written back to the buffer may actually be smaller than the number of input samples that have been read! The pending samples are buffered internally and will be returned in a subsequent call. In other words, samples are returned with a certain "delay". This means that the i-th output sample does not necessarily correspond to the i-th input sample! Still, the samples are returned in strict FIFO order. The exact delay can be determined by calling the getInternalDelay() function. At the end of the process, when all input samples have been read, to application shall call flushBuffer() in order to flush all pending samples.
Parameters:
samplesIn[c][i], as a double-precision floating point number. All indices are zero-based. All sample values live in the -1.0 to +1.0 range.samplesOut[c][i]. The size of the buffer must be sufficient! All indices are zero-based. All sample values live in the -1.0 to +1.0 range.samplesIn buffer, per channel. This also specifies the maximum number of output samples that can be written back to the samplesOut buffer.samplesOut buffer, per channel. Please note that this value can be smaller than the inputSize value. It can even be zero!Return value:
true if everything was successful or false if something went wrong.bool processInplace(
double **samplesInOut,
int64_t inputSize,
int64_t &outputSize
);This is the "main" processing function. It shall be called in a loop until all input audio samples have been processed.
The function works "in-place": It reads the original input samples from the specified buffer and then writes the normalized output samples, if any, back into the same buffer. So, the content of samplesInOut will not be preserved!
Note: A call to this function reads all provided input samples from the buffer, but the number of output samples that are written back to the buffer may actually be smaller than the number of input samples that have been read! The pending samples are buffered internally and will be returned in a subsequent call. In other words, samples are returned with a certain "delay". This means that the i-th output sample does not necessarily correspond to the i-th input sample! Still, the samples are returned in strict FIFO order. The exact delay can be determined by calling the getInternalDelay() function. At the end of the process, when all input samples have been read, to application shall call flushBuffer() in order to flush all pending samples.
Parameters:
samplesInOut[c][i], as a double-precision floating point number. The output samples, if any, will be stored at the corresponding locations, thus overwriting the input data. Consequently, the i-th output sample for the c-th channel will be stored at samplesInOut[c][i]. All indices are zero-based. All sample values live in the -1.0 to +1.0 range.samplesInOut buffer, per channel. This also specifies the maximum number of output samples that can be written back to the buffer.samplesInOut buffer, per channel. Please note that this value can be smaller than the inputSize value. It can even be zero!Return value:
true if everything was successful or false if something went wrong.bool flushBuffer(
double **samplesOut,
const int64_t bufferSize,
int64_t &outputSize
);This function shall be called at the end of the process, after all input samples have been processed via processInplace() function, in order to flush the pending samples from the internal buffer. It writes the next pending output samples into the output buffer, in FIFO order, if and only if there are still any pending output samples left in the internal buffer. Once this function has been called, you must call reset() before the processInplace() function may be called again! If this function returns fewer output samples than the specified output buffer size, then this indicates that the internal buffer is empty now.
Parameters:
samplesOut[c][i]. All indices are zero-based. All sample values live in the -1.0 to +1.0 range.samplesOut buffer. Please note that this value can be smaller than bufferSize size, if no more pending samples are left. It can even be zero!Return value:
true if everything was successfull or false if something went wrong.bool reset(void);Resets the internal state of the MDynamicAudioNormalizer instance. It normally is not required or recommended to call this function! The only exception here is: If you really want to process multiple independent audio files with the same normalizer instance, then you must call the reset() function after all samples of the current audio file have been processed (and all of its pending samples have been flushed), but before processing the first sample of the next audio file.
Return value:
true if everything was successfull or false if something went wrong.bool getConfiguration(
uint32_t &channels,
uint32_t &sampleRate,
uint32_t &frameLen,
uint32_t &filterSize
);This is a convenience function to retrieve the current configuration of an existing MDynamicAudioNormalizer instance.
Parameters:
Return value:
true if everything was successfull or false if something went wrong.bool getInternalDelay(
int64_t &delayInSamples,
);This function can be used to determine the internal "delay" of the MDynamicAudioNormalizer instance. This is the (maximum) number of samples, per channel, that will be buffered internally. The processInplace() function will not return any output samples, until (at least) this number of input samples have been read. This also specifies the (maximum) number of samples, per channel, that need to be flushed from the internal buffer, at the end of the process, using the flushBuffer() function.
Parameters:
Return value:
true if everything was successful or false if something went wrong.static void getVersionInfo(
uint32_t &major,
uint32_t &minor,
uint32_t &patch
);This static function can be called to determine the Dynamic Audio Normalizer library version.
Parameters:
static void getBuildInfo(
const char **date,
const char **time,
const char **compiler,
const char **arch,
bool &debug
);This static function can be called to determine more detailed information about the specific Dynamic Audio Normalizer build.
Parameters:
__DATE__ format.__TIME__ format.MSVC 2013.2).x86 or x64).true if this is a debug build; otherwise it will be set to false.static LogFunction *setLogFunction(
LogFunction *const logFunction
);This static function can be called to register a callback function that will be called by the Dynamic Audio Normalizer in order to provide additional log messages. Note that initially no callback function will be registered. This means that until a callback function is registered by the application, all log messages will be discarded. It is recommend to register your callback function before creating the first MDynamicAudioNormalizer instance. Also note that at most one callback function can be registered. Registering another callback function replaces the previous one. However, since a pointer to the previous callback function will be returned, multiple callback function can be chained – simply call the previous callback from the new one.
Parameters:
NULL to disable logging entirely.Return value:
NULL, if no callback function was registered before.The signature of the callback function must be exactly as follows, with standard cdecl calling convention:
void LogFunction(
const int logLevel,
const char *const message
);Parameters:
LOG_LEVEL_DBG = 0, LOG_LEVEL_WRN = 1 or LOG_LEVEL_ERR = 2. The application may evaluate this value to filter the log messages according to their importance. Log messages of level LOG_LEVEL_DBG are for debugging purposes, log messages of level LOG_LEVEL_WRN indicate potential problems, and log messages of level LOG_LEVEL_ERR indicate serious errors.strcpy() or strdup(), into a separate buffer.The source code of the Dynamic Audio Normalizer is available from one of the official Git repository mirrors:
https://github.com/lordmulder/DynamicAudioNormalizer.git (Browse)https://bitbucket.org/muldersoft/dynamic-audio-normalizer.git (Browse)https://gitlab.com/dynamic-audio-normalizer/dynamic-audio-normalizer.git (Browse)https://git.assembla.com/dynamicaudionormalizer.git (Browse)https://muldersoft.codebasehq.com/dynamicaudionormalizer/dynamicaudionormalizer.git (Browse)https://repo.or.cz/DynamicAudioNormalizer.git (Browse)The following build environments are currently supported:
Microsoft Windows with Visual C++, tested with Visual Studio 2013 and Visual Studio 2015:
You can build Dynamic Audio Normalizer by using the provided solution file: DynamicAudioNormalizer.sln
Optionally, you may run the deployment script z_build.bat, which will build the application in various configurations also create deployment packages. Note that you may need to edit the paths in the build script first!
Be sure that your environment variables JAVA_HOME (JDK path) and QTDIR (Qt4 path) are set correctly!
Linux with GCC/G++ and GNU Make, tested under Ubuntu 16.04 LTS and openSUSE Leap 42.2:
You can build Dynamic Audio Normalizer by invoking the provided Makefile via make command. We assume that the essential build tools (make, g++, libc, etc), as contained in Debian's build-essential package, are installed.
Optionally, you may pass the MODE=no-gui or MODE=mininmal options to Make in order to build the software without the GUI program or to create a minimal build (core library + CLI front-end only), respectively
Be sure that your environment variables JAVA_HOME (JDK path) and QTDIR (Qt4 path) are set correctly!
Building the Dynamic Audio Normalizer requires some third-party tools and libraries:
Windows developers are recommended to download our pre-compiled "all-in-one" prerequisites package:
Linux developers install prerequisites via package manager. We give examples for Ubuntu, openSUSE and CentOS here:
sudo apt install build-essentialsudo apt install openjdk-8-jdk python3-devsudo apt install libsndfile-dev libmpg123-dev qt4-defaultsudo apt install ant pandoc wgetsudo zypper install -t pattern devel_basissudo zypper install gcc-c++ java-1_8_0-openjdk-devel python3-develsudo zypper install libsndfile-devel mpg123-devel libqt4-develsudo zypper install ant pandoc wgetsudo yum groupinstall "Development Tools"sudo yum install java-1.8.0-openjdk-devel python3-develsudo yum install libsndfile-devel libmpg123-devel qt-develsudo yum install ant pandoc wgetstd::mutex, if supported → removes the dependency on PThread libraryprocess() function, i.e. an "out-of-place" version of processInplace()-t to explicitly specify the desired output format-d to explicitly specify the desired input libraryflushBuffer() is called before internal buffer is filled entirelygetConfiguration() API to retrieve the active configuration paramsreset() API to actually work as expected (some state was not cleared before)__declspec(thread), because it can crash libraries on Windows XP (details)setPass() API, because it is not applicable any moreflushBuffer() API, which provides a cleaner method of flushing the pending framesreset() API, which can be used to reset the internal state of the normalizer instancesetLogFunction API, which can be used to set up a custom logging callback functionA traditional audio compressor will prune all samples whose magnitude is above a certain threshold. In particular, the portion of the sample's magnitude that is above the pre-defined threshold will be reduced by a certain ratio, typically 2:1 or 4:1. In other words, the signal peaks will be flattened, while all samples below the threshold are passed through unmodified. This leaves a certain "headroom", i.e. after flattening the signal peaks the maximum magnitude remaining in the compressed file will be lower than in the original. For example, if we apply 2:1 reduction to all samples above a threshold of 80%, then the maximum remaining magnitude will be at 90%, leaving a headroom of 10%. After the compression has been applied, the resulting sample values will (usually) be amplified again, by a certain fixed gain factor. This factor will be chosen as high as possible without exceeding the maximum allowable signal level, similar to a traditional normalizer. Clearly, the compression allows for a much stronger amplification of the signal than what would be possible otherwise. However, due to the flattening of the signal peaks, the dynamic range, i.e. the ratio between the largest and smallest sample value, will be reduced significantly – which has a strong tendency to destroy the "vividness" of the audio signal! The excessive use of dynamic range compression in many recent productions is also known as the "loudness war".
The following waveform view shows an audio signal prior to dynamic range compression (left), after the compression step (center) and after the subsequent amplification step (right). It can be seen that the original audio had a large dynamic range, with each drumbeat causing a significant peak. It can also be seen how those peeks have been eliminated for the most part after the compression. This makes the drum sound much less catchy! Last but not least, it can be seen that the final amplified audio now appears much "louder" than the original, but the dynamics are mostly gone…
In contrast, the Dynamic Audio Normalizer also implements dynamic range compression of some sort, but it does not prune signal peaks above a fixed threshold. Actually it does not prune any signal peaks at all! Furthermore, it does not amplify the samples by a fixed gain factor. Instead, an "optimal" gain factor will be chosen for each frame. And, since a frame's gain factor is bounded by the highest magnitude sample within that frame, 100% of the dynamic range will be preserved within each frame! The Dynamic Audio Normalizer only performs a "dynamic range compression" in the sense that the gain factors are dynamically adjusted over time, allowing "quieter" frames to get a stronger amplification than "louder" frames. This means that the volume differences between the "quiet" and the "loud" parts of an audio recording will be harmonized – but still the full dynamic range is being preserved within each of these parts. Finally, the Gaussian filter applied by the Dynamic Audio Normalizer ensures that any changes of the gain factor between neighbouring frames will be smooth and seamlessly, avoiding noticeable "jumps" of the audio volume.
If you think that the Dynamic Audio Normalizer is not working properly, because it (seemingly) did not change your audio at all, you are almost certainly having the wrong expectations and the Dynamic Audio Normalizer actually is working just as it is supposed to work! Please keep in mind, that the Dynamic Audio Normalizer does not use compression, by default, which means that all local "peaks" are perfectly preserved. Also, the Dynamic Audio Normalizer never amplifies your audio more than what would bring the "loudest" local peak up to the threshold, i.e. no peak is ever allowed to exceed the threshold. Furthermore – and that is the important part – the Dynamic Audio Normalizer does not simply amplify each frame to its local maximum! Instead, it employs a Gaussian filter in order to "smooth" the amplification factors between neighboring frames, which ensures natural volume transitions and avoids noticeable "jumps" of the volume. But this also means that, due to the Gaussian smoothing filter, a particular frame may (and often will!) be amplified less than what its local maximum would allow.
Consequently, if the Dynamic Audio Normalizer did not change your audio in a noticeable way, it probably means that your audio simply could not be amplified any further – with the current Dynamic Audio Normalizer settings. This is not a "problem", it is just how the Dynamic Audio Normalizer is designed to work! Also keep in mind that the default settings of the Dynamic Audio Normalizer have been chosen rather "conservative", in order to make sure that the filter will not hurt the dynamics of the audio. Still, if you think that the Dynamic Audio Normalizer should be acting more "aggressively", you can try tweaking the settings. There are two settings that you may wish to adjust: Try a smaller filter size, or throw in some input compression. The smaller the filter size, the faster (more aggressively) the filter is going to react. At the same time, compression may help to reduce "outstanding" peaks that prevent higher amplification, but too much compression may easily hurt audio quality!
If you do not want the "quiet" and the "loud" parts of your audio to be harmonized, then the Dynamic Audio Normalizer simply may not be the right tool for what you are trying to achieve. It was purposely designed to work like that. Nonetheless, by using a larger filter size, the Dynamic Audio Normalizer may be configured to act more similar to a "traditional" normalization filter.
This warning indicates that the audio reader delivered more/less audio samples than what was initially projected. For most file formats, the projected number of audio samples should be accurate, in which case the warning may actually indicate an I/O error. When processing MPEG audio files, however, the projected number of audio samples is only a rough estimate. That's because MPEG audio files, like .mp2 or .mp3 files, do not use a proper file format; they are just a "loose" collection of MPEG frames. Consequently, there is no way to accurately determine the number of samples in an MPEG audio file, except for decoding the entire file – which would be way too slow. That's why MPEG audio decoders, like libmpg123, will try to estimate the total number of samples from the first couple of MPEG frames. Of course, this is not always accurate.
Consequently, when working with MPEG audio files, the warning about more/less audio samples than what was initially projected being read from the input file is most likely not a reason for concern; the warning can safely be ignored in that case. But, if the warning occurs with other types of audio files, please take care, since there probably was an I/O error!
Note: The Dynamic Audio Normalizer considers a discrepancy of the audio sample count of more than 25% as critical error.
This error message indicates that the program has encountered a serious problem. On possible reason is that your processor does not support the SSE2 instruction set. That's because the official Dynamic Audio Normalizer binaries have been compiled with SSE and SSE2 code enabled – like pretty much any compiler does by default nowadays. So without SSE2 support, the program cannot run, obviosuly. This can be fixed either by upgrading your system to a less antiquated processor, or by recompiling Dynamic Audio Normalizer from the sources with SSE2 code generation disabled. Note that SSE2 is supported by the Pentium 4 and Athon 64 processors as well as all later processors. Also every 64-Bit supports SSE2, because x86-64 has adopted SSE2 as "core" instructions. That means that every processor from the last decade almost certainly supports SSE2.
If your processor does support SSE2, but you still get the above error message, you probably have found a bug. In this case it is highly recommended to create a debug build and use a debugger in order to track down the cause of the problem.
This chapter lists the licenses that apply to the individual components of the Dynamic Audio Normalizer software.
The Dynamic Audio Normalizer library (DynamicAudioNormalizerAPI) is released under the
GNU Lesser General Public License, Version 2.1.
Dynamic Audio Normalizer - Audio Processing Library
Copyright (c) 2014-2017 LoRd_MuldeR <mulder2@gmx.de>. Some rights reserved.
This library is free software; you can redistribute it and/or
modify it under the terms of the GNU Lesser General Public
License as published by the Free Software Foundation; either
version 2.1 of the License, or (at your option) any later version.
This library is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with this library; if not, write to the Free Software
Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USAhttp://www.gnu.org/licenses/lgpl-2.1.html
The Dynamic Audio Normalizer command-line program (DynamicAudioNormalizerCLI) is released under the
GNU General Public License, Version 2.
Dynamic Audio Normalizer - Audio Processing Utility
Copyright (c) 2014-2017 LoRd_MuldeR <mulder2@gmx.de>. Some rights reserved.
This program is free software; you can redistribute it and/or
modify it under the terms of the GNU General Public License
as published by the Free Software Foundation; either version 2
of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program; if not, write to the Free Software
Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.http://www.gnu.org/licenses/gpl-2.0.html
The Dynamic Audio Normalizer log viewer program (DynamicAudioNormalizerGUI) is released under the
GNU General Public License, Version 3.
Dynamic Audio Normalizer - Audio Processing Utility
Copyright (c) 2014-2017 LoRd_MuldeR <mulder2@gmx.de>. Some rights reserved.
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program. If not, see <http://www.gnu.org/licenses/>.http://www.gnu.org/licenses/gpl-3.0.html
The Dynamic Audio Normalizer plug-in wrappers for SoX, VST and Winamp are released under the
MIT/X11 License.
Dynamic Audio Normalizer - Audio Processing Utility
Copyright (c) 2014-2017 LoRd_MuldeR <mulder2@gmx.de>. Some rights reserved.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.http://opensource.org/licenses/MIT
The Dynamic Audio Normalizer CLI program (DynamicAudioNormalizerCLI) incorporates the following third-party software:
libsndfile
C library for reading and writing files containing sampled sound through one standard library interface
Copyright (C) 1999-2016 Erik de Castro Lopo
Applicable license: GNU Lesser General Public License, Version 2.1
libmpg123
C library for decoding of MPEG 1.0/2.0/2.5 layer I/II/III audio streams to interleaved PCM
Copyright (C) 1995-2016 by Michael Hipp, Thomas Orgis, Patrick Dehne, Jonathan Yong and others.
Applicable license: GNU Lesser General Public License, Version 2.1
The Dynamic Audio Normalizer log viewer (DynamicAudioNormalizerGUI) incorporates the following third-party software:
Qt Framework
Cross-platform application and UI framework for developers using C++ or QML, a CSS & JavaScript like language
Copyright (C) 2014 Digia Plc and/or its subsidiary(-ies)
Applicable license: GNU Lesser General Public License, Version 2.1
QCustomPlot
Qt C++ widget for plotting and data visualization that focuses on making good looking, publication quality 2D plots
Copyright (C) 2011-2014 Emanuel Eichhammer
Applicable license: GNU General Public License, Version 3
The Dynamic Audio Normalizer VST wrapper (DynamicAudioNormalizerVST) incorporates the following third-party software:
The Dynamic Audio Normalizer can operate as a plug-in (effect) using the following third-party technologies:
Sound eXchange
Cross-platform command line utility that can convert various formats of computer audio files in to other formats
Copyright (C) 1998-2009 Chris Bagwell and SoX contributors
Virtual Studio Technology (VST 2.x)
Software interface that integrates software audio synthesizer and effect Plug-ins with audio editors and recording systems.
Copyright (C) 2006 Steinberg Media Technologies. All Rights Reserved.
VST PlugIn Interface Technology by Steinberg Media Technologies GmbH. VST is a trademark of Steinberg Media Technologies GmbH.
Winamp
Popular media player for Windows, Android, and OS X that supports extensibility with plug-ins and skins.
Copyright (C) 1997-2013 Nullsoft, Inc. All Rights Reserved.
e.o.f.
{kind=link}
{kind=link}